[ANTI-*] 0x000: Anti-Disassembly | Part one | (French version)
December 16, 2022 malware

Hello,
Le temps est venu de s’attaquer à un très gros morceau: les techniques d’Anti-Analyse. Et oui, les binaires sont des patients qui ne se laissent pas ausculter comme cela … En effet, les éditeurs commerciaux et les auteurs de malwares protègent leur binaire en y injectant un ou plusieurs mécanismes qui viennent complexifier et donc ralentir et diminuer le reverse de leur code,algo ou données. Ces techniques sont nombreuses et en perpétuelle évolution (comme toute situation “Le chat et la souris” ;-)
A ce stade, nous allons les diviser en 2 grandes catégories :
- Les techniques qui viennent complexifier l’analyse statique : Anti-Disassembly
- Les techniques qui vienne complexifier l’analyse dynamique : Anti-Debug
Dans cette longue série nous allons commencer par les techniques d’Anti-Disassembly.
Offuscation & Anti-Debug
Il existe aujourd’hui de nombreuses techniques pour complexifier le Reverse ou la simple compréhension d’un code binaire. Chaque acteur combine très souvent plusieurs moyens de protection. Certaines techniques complexifient l’analyse statique (par exemple en induisant en erreur les décompilateurs tel qu’IDA, Ghidra, …). D’autres ont pour objectif de ralentir l’analyse dynamique en utilisant des leurres qui viennent annihiler, voire parfois être offensif lors d’une exécutions sous Debuggeur.
Afin de rentrer dans le sujet, nous allons commencer par les contre-mesures de base puis nous irons voir, billet par billet, du côté des techniques de pointe (croyez-moi, il y a des choses assez dingues !! )
Complexifier l’Analyse Statique : Anti-Disassembly
Disassembly Desynchronization
Commençons par l’une des plus ancienne technique, mais parfois encore utilisée. Cette technique consiste à faire produire au désassembleur un code incorrect en plaçant des octets de données à des emplacements où ce dernier s’attend à trouver des octets d’instruction. Par exemple, l’exécution ne doit pas nécessairement revenir à l’instruction suivant un CALL après la fin de la fonction; l’adresse de retour de la fonction peut être délibérément modifiée pendant l’exécution de cette dernière. Ainsi, il devient possible de placer des octets de données après CALL pour perturber le désassemblage puisque le flow n’y passera jamais.
Prenons un exemple:
Voici le code assembleur original, c-à-d créé par l’auteur du malware (ici en MASM)
.code
main PROC
xor eax, eax
xor ebx, ebx
call loc_bizarre
db 'password',0
loc_bizarre:
pop ebx
INVOKE ExitProcess, eax
ret
main ENDP
Notre cher IDA ayant beau être un disassembler Flow-Oriented, il reversera le code binaire par le code asm suivant:
.text:00401010 _main@0 proc near ; CODE XREF: main()↑j
.text:00401010 xor eax, eax
.text:00401012 xor ebx, ebx
.text:00401014 call near ptr loc_40101E+1
.text:00401019 ; ---------------------------------------------------------------------------
.text:00401019 push 6F6C6C65h ; uExitCode
.text:0040101E
.text:0040101E loc_40101E: ; CODE XREF: main()+4↑p
.text:0040101E add [ebx+50h], bl
.text:00401021 call _ExitProcess@4 ; ExitProcess(x)
.text:00401026 ; ---------------------------------------------------------------------------
.text:00401026 retn
.text:00401026 _main@0 endp
Vous constatez qu’IDA a interprété les octets de la donnée ‘password’ située juste derrière notre CALL comme du code :-( L’auteur du malware est donc satisfait car il fait 2 choses en une:
- Il masque sa data
- Il embrouille IDA et donc la personne qui Reverse
Heureusement il est possible avec IDA ou Ghidra de convertir en Data le code produit (et l’inverse également). Pour cela on sélectionne notre octet de code douteux, puis on appuie sur la touche D pour lui dire “Hey mec, c’est de la Data ces BYTES;-)”. On se retrouve ensuite avec un code désassemblé qui reproduit bien cette fois-ci le code original et ne masque plus cette précieuse chaine de caractères :
.text:00401010 _main@0 proc near ; CODE XREF: main()↑j
.text:00401010
.text:00401010 ; FUNCTION CHUNK AT .text:0040107C SIZE 00000FC0 BYTES
.text:00401010
.text:00401010 xor eax, eax
.text:00401012 xor ebx, ebx
.text:00401014 call loc_401022
.text:00401014 ; ---------------------------------------------------------------------------
.text:00401019 db 70h ; p
.text:0040101A db 61h ; a ; a
.text:0040101B db 73h ; s
.text:0040101C db 73h ; s ; s
.text:0040101D db 77h ; w
.text:0040101E db 6Fh ; o ; o
.text:0040101F db 72h ; r
.text:00401020 db 64h ; d ; d
.text:00401021 db 0
.text:00401022 ; ---------------------------------------------------------------------------
.text:00401022
.text:00401022 loc_401022: ; CODE XREF: main()+4↑p
.text:00401022 pop ebx
.text:00401023 push eax ; uExitCode
.text:00401024 call _ExitProcess@4 ; ExitProcess(x)
.text:00401029 ; ---------------------------------------------------------------------------
.text:00401029 retn
.text:00401029 _main@0 endp
Que faut-il en comprendre ?
Et bien qu’en connaissant le fonctionnement interne d’IDA (on ne parlera même pas ici des autres …) et bien les auteurs de malwares (ou toute personne qui souhaiterait complexifier le reverse de son binaire) peuvent occulter un premier niveau d’analyse.
Voyons maintenant quelques autres tricks de Disassemby Desynchronization.

Le jump inconditionnel
La technique ici consiste à construire un jump inconditionnel en juxtaposant un JZ et un JNZ sur la même destination.
Voici le code original tel qu’écrit par son auteur:
.code
main PROC
mov eax, 0
test eax, eax
jz short near ptr loc_chelou
jnz short near ptr loc_chelou
db 'http://c2.naptax.re/', 0
loc_chelou:
pop ebx
add ebx, 10
INVOKE ExitProcess, eax
ret
main ENDP
END main
Mais notre IDA est un peu flouté par cette pattern et traduit donc les octets qui suivent le JNZ comme du code et non comme les données (quelles sont). Résultat, c’est du n’importe quoi ;-)
.text:00401010 ; int __cdecl main(int argc, const char **argv, const char **envp)
.text:00401010 _main@0 proc near ; CODE XREF: main()↑j
.text:00401010
.text:00401010 argc = dword ptr 4
.text:00401010 argv = dword ptr 8
.text:00401010 envp = dword ptr 0Ch
.text:00401010
.text:00401010 ; FUNCTION CHUNK AT .text:0040105A SIZE 00000FF7 BYTES
.text:00401010
.text:00401010 mov eax, 0
.text:00401015 test eax, eax
.text:00401017 jz short near ptr loc_40102F+1
.text:00401019 jnz short near ptr loc_40102F+1
.text:0040101B push 3A707474h
.text:00401020 das
.text:00401021 das
.text:00401022 arpl [edx], si
.text:00401024 outs dx, byte ptr cs:[esi]
.text:00401026 popa
.text:00401027 jo short loc_40109D
.text:00401029 popa
.text:0040102A js short loc_40105A
.text:0040102C jb short loc_401093
.text:0040102E das
.text:0040102F
.text:0040102F loc_40102F: ; CODE XREF: main()+7↑j
.text:0040102F ; main()+9↑j
.text:0040102F add [ebx-7Dh], bl
.text:00401032 retn
.text:00401032 ; ---------------------------------------------------------------------------
.text:00401033 db 0Ah
.text:00401034 ; ---------------------------------------------------------------------------
.text:00401034 push eax ; uExitCode
.text:00401035 call _ExitProcess@4 ; ExitProcess(x)
.text:0040103A ; ---------------------------------------------------------------------------
.text:0040103A retn
.text:0040103A _main@0 endp ; sp-analysis failed
Positionnons nous juste derrière ce JNZ, et aidons un peu IDA en tapant sur D pour lui dire (“Hey là, c’est de la Data mec”). Et hop, on trouve le vrai code, et donc l’url du serveur C2, c’était le FLAG ;-)
.text:00401010 ; int __cdecl main(int argc, const char **argv, const char **envp)
.text:00401010 _main@0 proc near ; CODE XREF: main()↑j
.text:00401010
.text:00401010 argc = dword ptr 4
.text:00401010 argv = dword ptr 8
.text:00401010 envp = dword ptr 0Ch
.text:00401010
.text:00401010 ; FUNCTION CHUNK AT .text:0040105B SIZE 00000FF7 BYTES
.text:00401010
.text:00401010 mov eax, 0
.text:00401015 test eax, eax
.text:00401017 jz short loc_401031
.text:00401019 jnz short loc_401031
.text:00401019 ; ---------------------------------------------------------------------------
.text:0040101B aHttpsC2NaptaxR db 'https://c2.naptax.re/',0
.text:00401031 ; ---------------------------------------------------------------------------
.text:00401031
.text:00401031 loc_401031: ; CODE XREF: main()+7↑j
.text:00401031 ; main()+9↑j
.text:00401031 pop ebx
.text:00401032 add ebx, 0Ah
.text:00401035 push eax ; uExitCode
.text:00401036 call _ExitProcess@4 ; ExitProcess(x)
.text:0040103B ; ---------------------------------------------------------------------------
.text:0040103B retn
Ok à ce stade là, vous avez du comprendre la technique du Disassembly Desynchonisation, passons à la suivante.
Impossible Disassembly
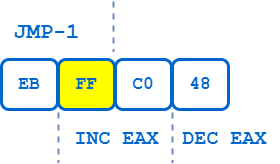
Là encore, la technique ne date pas d’hier, mais étant toujours utilisée il est important de la connaître. Il s’agit ici d’insérer des octets faisant partie de 2 instructions. Bien qu’une telle situation soit parfaitement gérée par le processeur, le désassembleur lui ne comprend pas cette pattern “multi-instructions” et procédera à désassemblage incohérent.
Le schéma ci-dessous propose un exemple d’une telle situation. La première instruction de cette séquence de 4 octets est une instruction JMP sur 2 octets. La cible du saut est le deuxième octet de lui-même. Cela ne provoque pas d’erreur, car l’octet FF est le premier octet de la prochaine instruction de 2 octets, INC EAX.
Implémentons cette pattern avec un peu de C et d’inline asm :
#include <stdio.h>
int main() {
printf("Hello, World!\n");
__asm__(".byte 0xeb, 0xff, 0xc0");
printf("NOT Show in IDA\n");
return 0;
}
Et voici comment IDA nous désassemble le binaire généré par ce code !
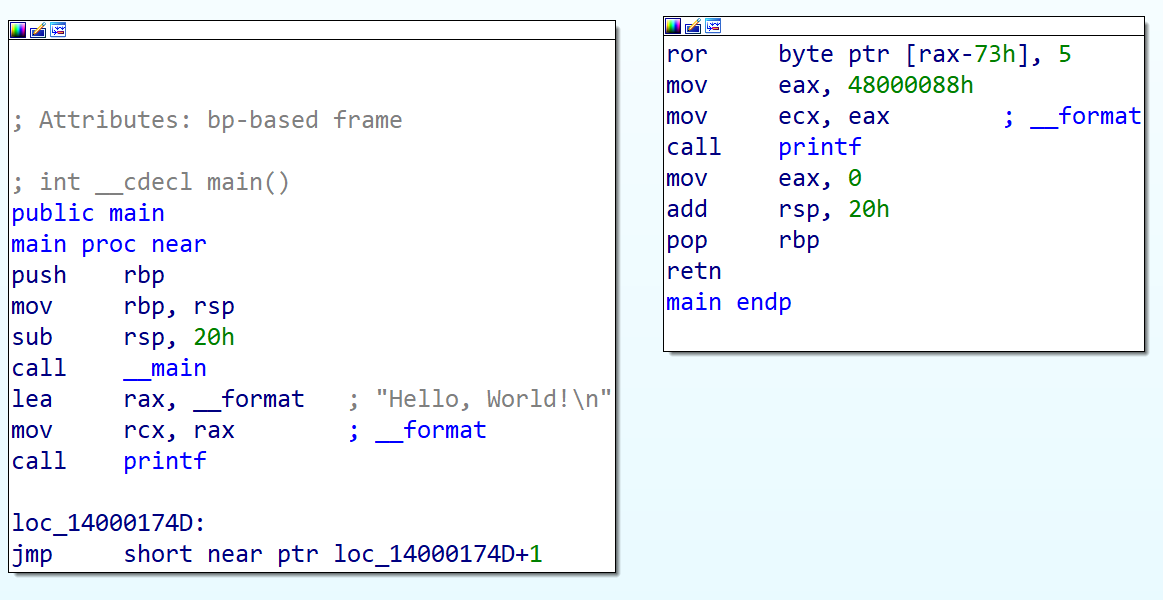
Un et un seul print (celui de “Hello World \n”)
Si maintenant, nous commentons la production de ces 4 octets :
#include <stdio.h>
int main() {
printf("Hello, World!\n");
// __asm__(".byte 0xeb, 0xff, 0xc0");
printf("NOT Show in IDA\n");
return 0;
}
Nous obtenons d’IDA le désassemblage suivant :
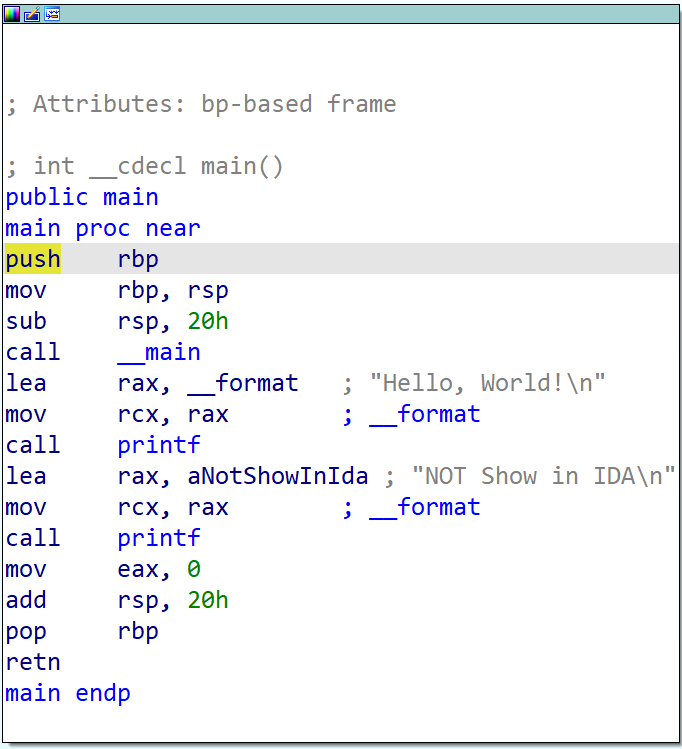
Nous voyons alors bien nos 2 printf.
Évidement dans les malwares la pattern est utilisée de manière plus large que sur 4 octets; néanmoins le principe est toujours le même.

Obscuring Control Flow
Cette technique consiste à ne pas utiliser les opérandes de type JUMP ou CALL pour contrôler le flux d’exécution, rendant ainsi complexe, voire impossible sa rétro-engineering automatique.
En place de ces instructions, le code utilise les structures de l’OS permettant de gérer les exceptions (et d’une manière plus générale toutes les techniques et moyens de Callback).
Parmi ces structures de gestion d’exception, l’on retrouve
Sous Windows
Structure Exception Handler (SEH)Vector Exception Handler (VEH)Unhandled Exception Handler
Sous Linux
- Utilisation des signaux Unix
- Instructions
setjmp et longjmp
Le malware déclenche alors volontairement des exceptions afin d’appeler le callback en charge de la gestion de ce type d’exception. Ainsi, le flux d’execution est sous contrôle et son reverse (en analyse statique) devient beaucoup plus complexe pour l’analyste :-(

Abusing the Return Pointer
Cette technique d’anti-disassembly consiste,là encore, à embrouiller nos IDA, GHIDRA et HOPPER en obscurcissant le contrôle du flux d’execution. Cette fois-ci en utilisant l’instruction retn de manière atypique mais valide.
Un bref rappel sur les instructions call et retn :
callréalise un jump inconditionnel (jmp) et pousse une adresse de retour sur la stack : donc un PUSH et un JMPretntire l’adresse de retour de la stack et y réalise un jmp : donc un POP et un JMP
Bien que call et retn fonctionnent ensemble, rien ne nous empêche d’utiliser un retn en dehors de tout contexte de call. Posons simplement sur le haut de la pile (push) l’adresse sur laquelle nous souhaitons brancher le flux d’execution, puis appelons retn pour que ce dernier pop la la valeur et y réalise le JMP.
Les désassembleurs ont du mal à interpréter ces jump atypiques, et génèrent donc un code asm incohérent pour la rétro-analyse.

API Calling Obsfuscation
Très souvent utilisée dans les malwares, cette technique consiste a masquer à l’analyste les fonctions d’API externes appelées. Il existe pour cela plusieurs techniques, mais la plus répandue est la technique qui consiste à identifier les fonctions d’API par leur hash.
Ces appels API par le hash de leurs fonctions fonctionnent selon le principe suivant :
Il faut au préalable que l’auteur du malware pré-calcule le hash du nom de l’API ET le hash des adresses des fonctions qu’il utilise dans son code (via l’
Export Address Tablede la DLL)L’auteur du malware implémente une fonction de recherche d’API par son hash
Puis l’auteur fait ses call API externes à travers cette correspondance Hash -> API
En langage de haut niveau (ex: C), il est nécessaire de déclarer les prototypes de chaque fonction, et ce, afin de gagner en confort d’implémentation
Ainsi, les outils d’analyse et l’analyste ne voient pas “en clair dans les String ou l’IAT” les fonctions API utilisées. Et comme vous le savez l’analyse des fonctions API externes utilisées renseigne assez vite sur les opérations réalisées et la nature d’un malware.
Il faut néanmoins veiller à utiliser/implémenter une fonction de hash ne générant pas de collision. Parmi les nombreuses fonctions de hash disponibles, on retrouve souvent : djb2 algo ici. Elle a l’avantage td’être simple, ne générant pas de collision et rapide. Néanmoins du point de vue attaquant, cet algo a l’inconvénient d’utiliser ce que j’appelle “des constantes signatures”. Ces constantes signatures permettront à l’analyste d’identifier la présence de cette fonction de hash. Dans le cas de djb2 la constante signature est 0x1505h (5381d). C’est pourquoi les Malwares les plus avancés masquent cette constante en la décomposant ou la chiffrant.
Nous rentrerons dans le détail plus tard dans un petit billet dédié à ce sujet, mais sachez qu’il est assez simple de scripter le reverse de cette technique fort utilisée.

Voici nous avons vu quelques-unes des techniques qui viennent complexifier l’analyse statique d’un code binaire. Il en existe bien d’autres, dont la principale fait l’objet de notre prochain article : Packer et unpacking.